Mixture Reduction
Mixture models provide a principled way to capture heterogeneity in data by positing that observations are generated from a combination of latent components. A classical example is the Gaussian mixture model, which serves as a flexible proxy for complex distributions.
While mixture models are powerful, they can quickly become unwieldy as the number of components grows — in Bayesian filtering, for instance, components can proliferate exponentially with time. Mixture reduction (MR) seeks to approximate a large mixture with a simpler one that remains faithful to the data-generating structure.
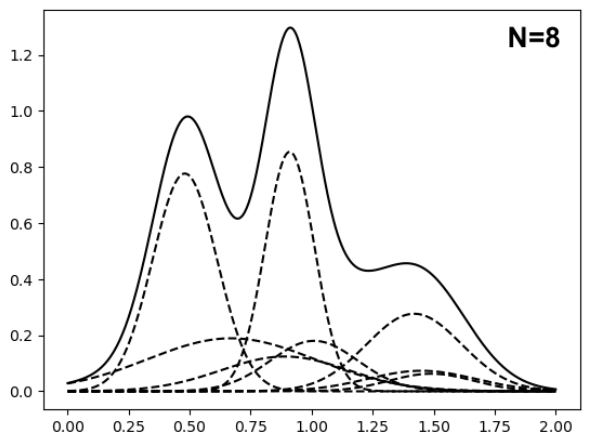
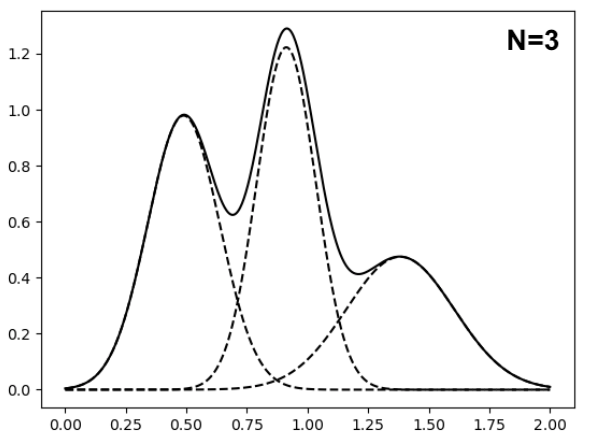
Figure 1: Two Gaussian mixtures of different orders with similar density functions (solid lines). Dashed lines are component densities.
Our approach: Optimal transport
To bridge the gap between heuristic and principled MR methods, we proposed a perspective grounded in optimal transport. We define the MR estimate as the minimizer of a composite optimal transportation divergence between candidate and original mixtures, and designed an iterative majorization–minimization algorithm that is computationally efficient, comes with provable convergence guarantees, and is flexible enough to trade off running time and statistical accuracy.
Key paper: Zhang, Q., Zhang, A. G., and Chen, J. (2024). Gaussian Mixture Reduction With Composite Transportation Divergence. IEEE Transactions on Information Theory, 70(7). [Journal] [arXiv] [Code] [Slides]
Application 1: Federated learning of finite mixture models
In federated learning of finite mixture models, massive heterogeneous data are partitioned across many clients. A major obstacle is label switching, which breaks naïve split-and-conquer strategies because component estimates on different clients are not aligned.
We addressed this by averaging mixing distributions across clients and applying MR to project the result back into the correct parameter space. The resulting estimator is computationally efficient, achieves the optimal convergence rate, and is asymptotically equivalent to the global MLE.
To handle Byzantine failures (clients transmitting corrupted information), we developed DFMR — a robust extension that retains both efficiency and statistical guarantees.
Key papers:
-
Zhang, Q. and Chen, J. (2022). Distributed Learning of Finite Gaussian Mixtures. JMLR, 23(1). [Journal] [arXiv] [Code] [Talk] [Poster]
-
Zhang, Q., Tan, Y. S., and Chen, J. (2026). Byzantine-Tolerant Distributed Learning of Finite Mixture Models. JRSSB. [Journal] [arXiv] [Code] [Slides]
Application 2: 3D Gaussian Splatting compaction
3D Gaussian Splatting (3DGS) is a state-of-the-art technique for reconstructing 3D scenes from 2D images, representing scenes with millions of Gaussians. While highly expressive, this introduces substantial storage and rendering costs. Existing compaction strategies typically rely on pruning, which often sacrifices geometric fidelity.
Our approach interprets the Gaussians as a mixture model and applies principled MR for compaction — naturally preserving geometric structure and avoiding distortion. We designed a novel cost function with closed-form, low-cost updates and a block-wise algorithm guided by KD-trees for scalability. The result: up to 90% Gaussian reduction while outperforming pruning-based methods.
Key paper: Wang, T., Li, M., Zeng, G., Meng, C., and Zhang, Q. (2025). Gaussian Herding across Pens. NeurIPS 2025 Spotlight. [Paper] [arXiv] [Code] [Poster]